Denizenslab
Cognitive Computing in Biological and Artificial Systems @ TU Berlin

TU Berlin, MAR building
Marchstraße 23
10587 Berlin, Germany
Our group’s goal is to deepen the connection between artificial intelligence, data science, and neuroscience in research and teaching. We develop computational models of human brain responses that were acquired under ecologically valid conditions. By exploring language representation, communication, and cognition in biological and artificial systems, we aim to enhance our understanding of the neural and computational bases of brain processes under ecologically valid conditions. We thereby aim to understand and optimize artificial neural language models by integrating insights from brain research to ultimately expand both the explainability of artificial systems and our understanding of the human brain.
news
| Mar 29, 2026 | Our lab members are giving a tutorial on “Encoding and Decoding Language in the Brain with Language Models” at EACL 2026 in Rabat, Morocco! |
|---|---|
| Mar 04, 2026 |
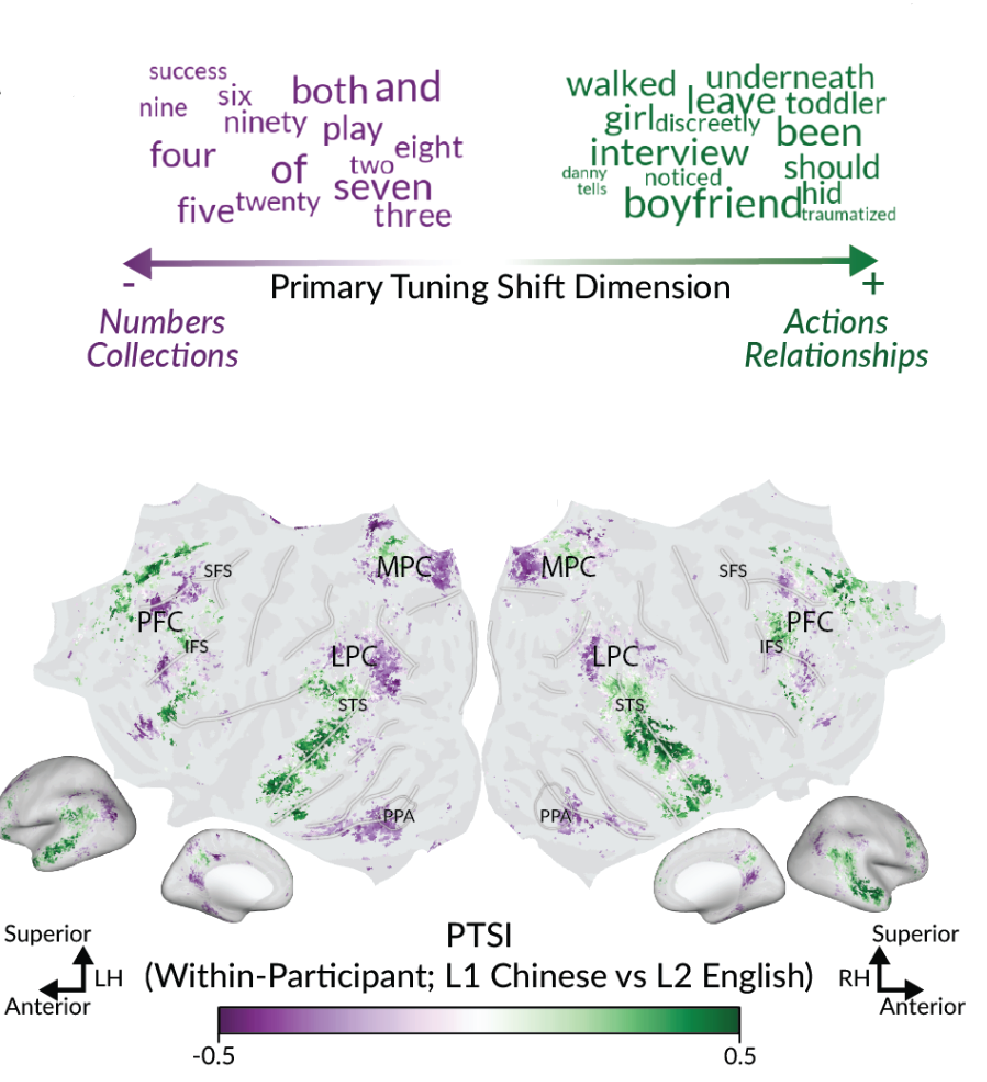
Our new paper in Proceedings of the National Academy of Sciences, first-authored by Dr. Catherine Chen, shows that bilingual language comprehension relies on shared semantic representations in the brain that are systematically modulated by each language. The study is also featured in PNAS’s “In This Issue” section.
Check out also our interactive brain viewer here.

|
| Jan 28, 2026 | Our PI Prof. Dr. Fatma Deniz has been appointed to the German Council for Sustainable Development (RNE) by Federal Chancellor Friedrich Merz. As a computer scientist at the interface of neuroscience, AI and society, she stands for evidence-based transformation and a future-oriented sustainability policy. |
selected publications
-
-
Encoding models in functional magnetic resonance imaging: the Voxelwise Encoding Model frameworkSep 2025